PermaVid
Consistent Video Generation Across Edits via Disentangled Context Memory
1Shanghai Jiao Tong University ·
2Stanford University ·
3S-Lab, NTU ·
4CUHK ·
5Shanghai Innovation Institute
Abstract:
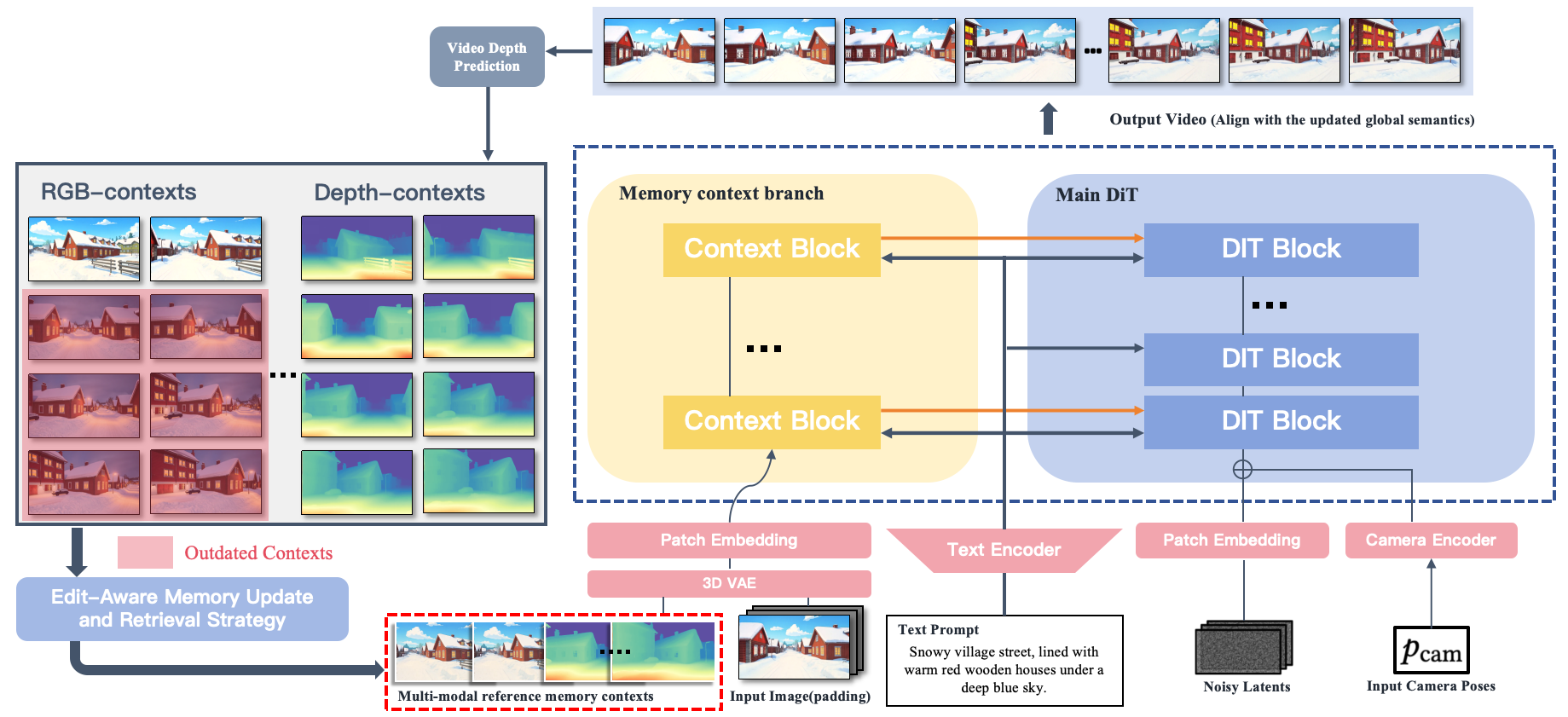
Consistent video generation under editing operations requires persistence: when edits modify scene appearance or layout, subsequent generations should remain coherent across time and viewpoints. However, existing memory designs struggle to maintain long-term consistency after such modifications, as stored contexts may become outdated or invalid. To address this, we propose PermaVid, a novel framework built upon a multi-modal context memory that disentangles spatial context into semantic appearance and geometric structure, together with an edit-aware memory update and retrieval strategy that keeps memory evolution aligned with subsequent observations. Specifically, we develop two complementary memory banks: an RGB context memory that captures appearance-aware observations while implicitly encoding geometry, and a depth context memory that preserves geometry-only structure disentangled from semantics. Building on this design, we introduce a memory-guided video generation model that performs multi-modal feature fusion under reference conditions drawn from mixed-modality memory contexts. Experiments demonstrate that our method maintains strong long-term semantic and structural consistency after edits, significantly outperforming state-of-the-art methods.